NoSQL Schema Extraction
Many data sources were not developed using a schema-first approach. For these datasets, neither an explicit schema nor a complete list of semantic constraints is available in advance.
In all these cases, reverse engineering methods are needed to reconstruct the schema and certain constraints from the data. We have developed such methods to derive a schema as well as schema statistics and information about structural outliers in datasets.
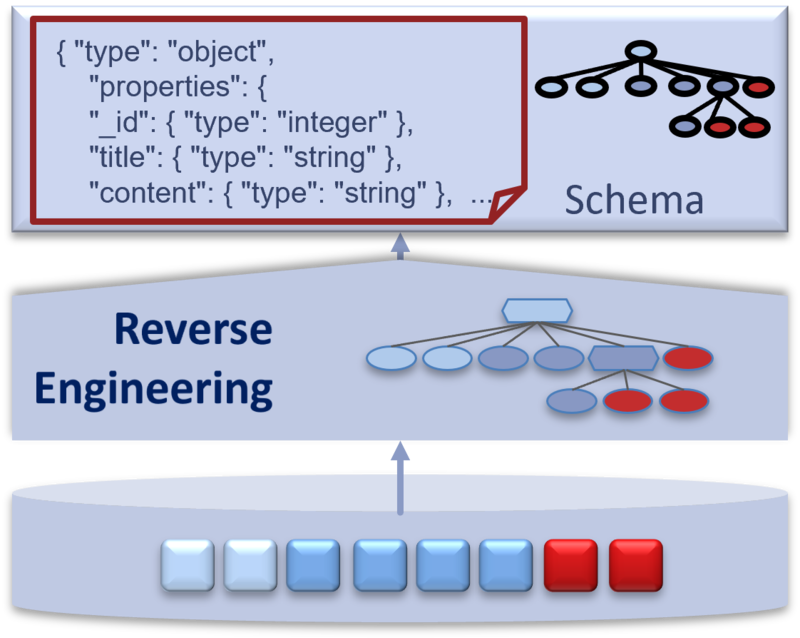
A solution for deriving a schema overview (JSON schema) from JSON data, additional schema statistics and outliers in the datasets can be found here:
- Meike Klettke, Uta Störl, Stefanie Scherzinger: Schema Extraction and Structural Outlier Detection for NoSQL Data Stores. Copyright: Gesellschaft für Informatik, BTW 2015, (article, slides)
Schema versions (in JSON schema syntax) can be derived from JSON documents as well as the evolution operations that transform one schema version into the subsequent one, this is described in this publication:
- Meike Klettke, Uta Störl, Manuel Shenavai, Stefanie Scherzinger: NoSQL Schema Evolution and Big Data Migration at Scale, 4th Scalable Cloud Data Management Workshop (SCDM) @ IEEE Big Data Conference, Washington, D.C., USA, December 2016, (article)
Information how these schema extraction approaches are integrated into the NoSQL evolution approach can be found here
and in theses pubications:
- Uta Störl, Meike Klettke: Darwin: A Data Platform for NoSQLSchema Evolution Management and Data Migration, DataPlat@EDBT, 2022 (pdf)
- Uta Störl, Meike Klettke, Stefanie Scherzinger: NoSQL Schema Evolution and Data Migration: State-of-the-Art and Opportunities. EDBT 2020: 655-658, (pdf)
Meike Klettke - 14.08.2024 10:13 
